Introduction au machine learning
Kezako?
Machine learning ⊂ Intelligence artificielle
Permet de faire prendre des décisions à une machine, basées sur un processus d'apprentissage préalable, par le biais de données empiriques.
Applications possibles
- Recommandation (Amazon, Ebay, Netflix…)
- Classification de contenu (gestion de courrier, antispam…)
- Analyse de sentiment
- Reconnaissance optique de caractères (OCR)
- Reconnaissance vocale
- détection de fraude/d'erreur
- …
Pourquoi?
- Expérience personnalisée pour l'utilisateur
- Moins de travail rébarbatif (classification manuelle, etc)
- Savoir comment positionner un nouveau produit
- …
Toolbox et algorithmes
- Recommendation: colaborative filtering, item-based filtering…
- Clustering: K-means, Spectral Clustering
- Régression: SVR
- Réduction de dimensions: ACP
- Classification: Random forest, Decision tree, Naive Bayes, SVM
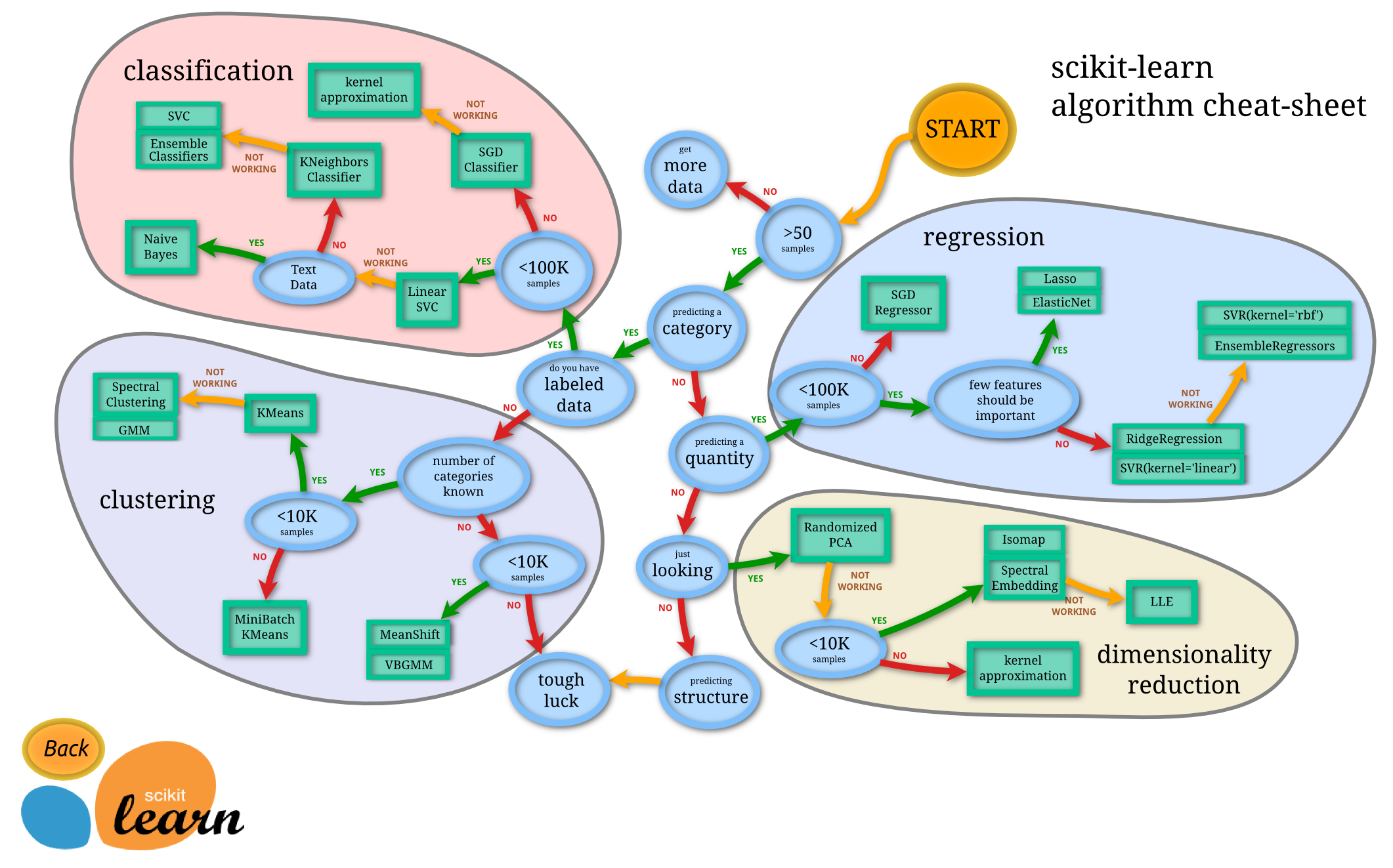
😨 Comment s'y retrouver?
In [39]:
Image(filename='img/ml_map.png')
Out[39]:
Clustering: l'art de faire des groupes
- Supervisé: nombre de clusters connus à l'avance
- Non supervisé: l'algorithme propose le nombre de clusters le plus cohérent possible
Exemple: clustering visuel dans une page web
In [40]:
IFrame(src='http://www.grandlyon.com/Fete-des-lumieres.4977.0.html', width=1000, height=800)
Out[40]:
In [41]:
Image('img/clustering2.png')
Out[41]:
Classsification
"Dis moi à quoi tu ressembles et je te dirais qui tu es."
Associer une classe / un label à un élément
- classification visuelle (y a t-il un lolcat dans cette image?)
- classification textuelle (quel est le sujet de ce texte?)
- classification sonore (reconnaissance de voix)
Demo: sport ou politique?
In [43]:
data = requests.get(
'http://balthazar-rouberol.com/slides/mlintro/data/classified-articles.json').json()
stopwords = [word.strip() for word in codecs.open('data/stopwords.txt', 'r', 'utf-8')]
In [44]:
text_vectorizer = TfidfVectorizer(
max_df=4000, # max number of relevant tokens
min_df=6, # min number of relevant tokens
max_features=500, # maximum number of features
strip_accents='unicode', # replace all accented unicode
# chars by their corresponding ASCII char
stop_words=stopwords,
analyzer='word', # features made of words
token_pattern=r'\w{4,}', # tokenize only words of 4+ chars
ngram_range=(1, 1), # features made of a single tokens
use_idf=True, # enable inverse-document-frequency reweighting
smooth_idf=True, # prevents zero division for unseen words
sublinear_tf=False)
In [45]:
# vetorize all training articles
train = articles['train']['sport'] + articles['train']['politics']
text_vector = text_vectorizer.fit_transform(train)
# trainin rubric array
rubrics = ['sport'] * len(articles['train']['sport']) + \
['politics'] * len(articles['train']['politics'])
In [48]:
clf = LinearSVC()
clf.fit(text_vector, rubrics)
In [47]:
def predict_rubric(article):
"""Vectorize the article using the training text vectorizer
and predict the article rubric.
"""
article_vector = text_vectorizer.transform([article])
return clf.predict(article_vector)
Toolkits python
NLTK(NLP uniquement)nlpy(classification, regression, clustering)PyBrain(réseaux de neurones)bigml(API REST)scikit-learn(classification, régression, clustering, sélection de features, visualisation, etc)- ...
scikit-learn: +/-
- très bonne documentation: beaucoup d'exemples!
- énormément d'outils
- API consistante
- rapide (basé sur
numpy&scipy) - courbe d'apprentissage conséquente
- pas d'outils de recommendations (item-based filtering, collaborative filering, etc)